NDLR : pour s’amuser un peu, tout en découvrant les méandres de l’IA !
Le réseau de neurones artificiels copie le cerveau humain pour favoriser l’apprentissage. Il s’agit donc d’un système qui se base sur le fonctionnement du cerveau humain pour l’adapter à des ordinateurs équipés de fonctions d’intelligence artificielle.
Grâce au réseau de neurones artificiels, l’ordinateur arrive à résoudre des problèmes de manière autonome. Le réseau améliore aussi les capacités de l’ordinateur.

Appréhension du concept d’apprentissage par l’expérience
1. Introduction au Machine Learning
« Aujourd’hui, nous allons découvrir le monde fascinant du machine learning, une branche de l’intelligence artificielle. Imaginez un robot qui apprend de ses erreurs ou un ordinateur qui peut prédire la météo. C’est le machine learning ! Contrairement à la programmation traditionnelle où nous donnons des instructions précises à l’ordinateur, ici, la machine apprend à partir des données qu’elle reçoit.

Dans de nombreux domaines, le machine learning peut révolutionner notre façon de travailler. Par exemple, il peut aider à détecter les maladies des plantes bien plus tôt que l’humain, faire des projections sur l’évolution de l’aménagement d’un espace avec le végétal etc. Maintenant, voyons comment cela s’applique à la reconnaissance d’images. »
2. Reconnaissance d’Images
« La reconnaissance d’images est une partie passionnante du machine learning. C’est comme donner des yeux à l’ordinateur ! Grâce à cela, l’ordinateur peut identifier et classer des objets dans des images, comme différencier une feuille saine d’une feuille malade.

Pour comprendre comment cela fonctionne, imaginons une photo numérique. Elle est composée de petits points appelés pixels. L’ordinateur analyse ces pixels pour reconnaître des formes, des couleurs et d’autres caractéristiques. C’est ainsi qu’il apprend à identifier les signes de maladies sur les feuilles des plantes. Maintenant, passons à la pratique avec notre propre projet de reconnaissance d’images. »
3. Préparation du Dataset
« Pour entraîner notre ordinateur, nous avons besoin d’images de feuilles. Allons sur le site http://lootbox.fr/wp-content/cours/IA/datasets/ et sélectionnons ensemble des images de feuilles saines et malades. Assurez-vous de choisir une variété d’images pour chaque catégorie. C’est important pour que notre modèle soit précis et fiable.
Une fois les images sélectionnées, nous allons les diviser en deux catégories : ‘Saines’ et ‘Malades’. Cette organisation aidera l’ordinateur à apprendre et à faire la différence entre les deux. C’est un peu comme créer un album photo trié pour un ami. Vous êtes prêts ? Allons-y ! »
4. Upload des Images sur Vittascience
Maintenant, connectons-nous à https://fr.vittascience.com. Ici, nous allons télécharger nos images et les classer dans les catégories que nous avons créées. Suivez-moi pas à pas. Cliquez sur ‘Télécharger’, sélectionnez vos images, puis attribuez-les à la bonne catégorie. C’est un processus simple, mais soyez attentifs aux détails. Chaque image bien classée compte pour l’apprentissage de notre modèle.
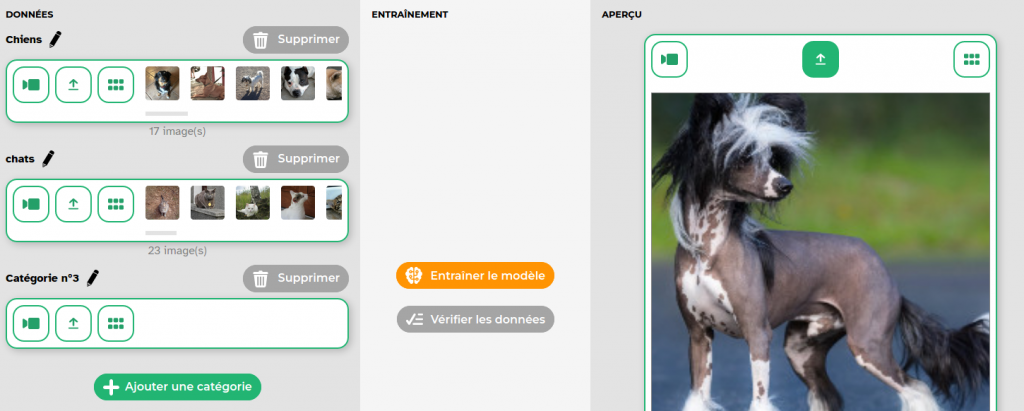
5. Entraînement du Modèle
Après avoir téléchargé nos images, il est temps d’entraîner notre modèle. Lors de l’entraînement, l’ordinateur va analyser les images et apprendre à distinguer les feuilles saines des malades. C’est un peu comme apprendre à jouer d’un instrument – plus on pratique, mieux on devient.

Nous allons lancer le processus d’entraînement sur Vittascience. Pendant qu’il travaille, l’ordinateur va créer un ‘modèle’ basé sur nos images, ce qui lui permettra de reconnaître les feuilles dans de nouvelles images. C’est fascinant de voir comment quelques images peuvent enseigner tant de choses à une machine !
6. Test du Modèle et Conclusion
Enfin, testons notre modèle. Pour cela, nous allons utiliser des images qu’il n’a jamais vues pendant l’entraînement. C’est le moment de vérité pour voir si notre modèle peut correctement identifier des feuilles saines et malades.
Regardons les résultats. Sont-ils précis ? Y a-t-il des erreurs ? Cela nous montre les limites et les possibilités de notre modèle. N’oubliez pas, le machine learning est un outil puissant, mais il dépend de la qualité des données qu’il reçoit.
Pour conclure, vous avez vu comment le machine learning et la reconnaissance d’images peuvent jouer un rôle crucial en agriculture. Vous avez réalisé un projet réel qui pourrait, un jour, aider les agriculteurs !
Visualisez comment ça fonctionne !

NDLR : si vous êtes intéressé par la façon dont cela fonctionne poursuivez ci-dessous ! Sinon, rendez-vous à la leçon suivante.
Voici comment fait la machine pour apprendre :
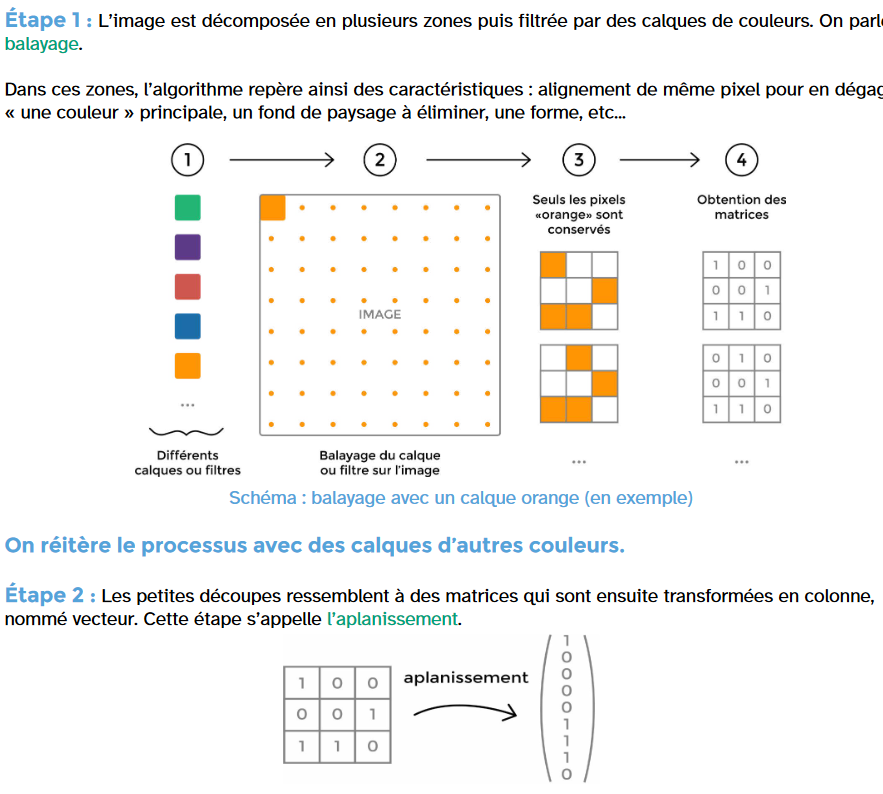
Source vittascience
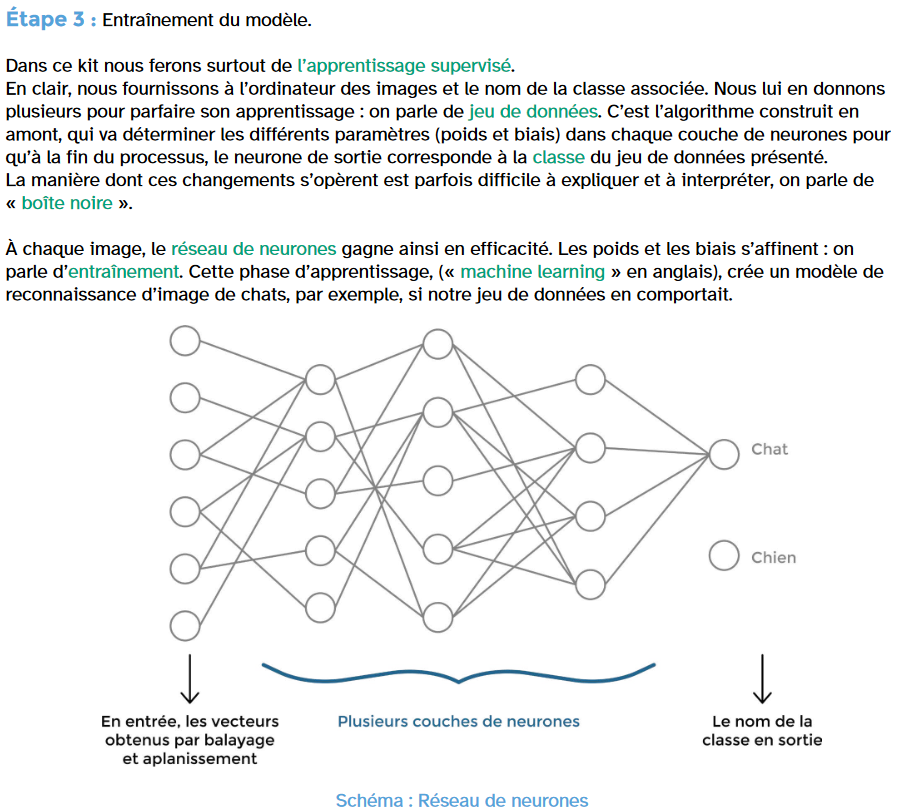
Et derrière la boîte noire, que se passe-t-il ?
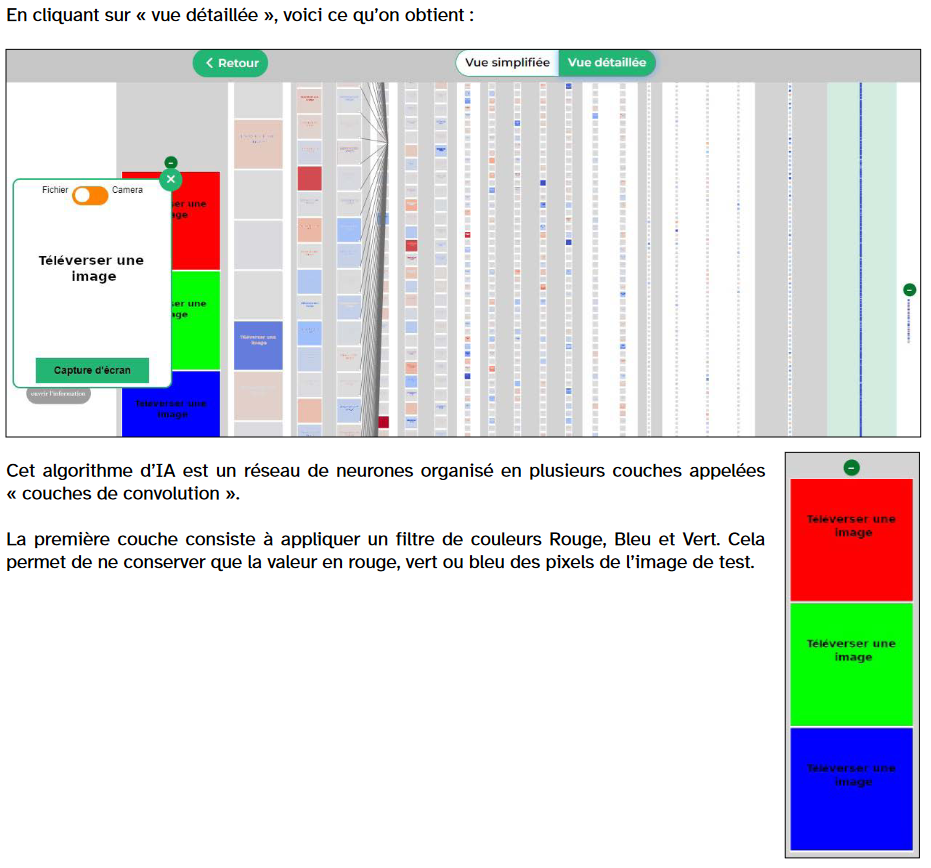

Explication
… Mais les beaux discours c’est bien aussi :
Un neurone est comme une petite unité de traitement dans un système d’intelligence artificielle. Chaque neurone a une valeur qui détermine son rôle dans le système. Une fonction spéciale, appelée fonction d’activation, calcule ce que fait chaque neurone. Cela détermine combien de neurones doivent travailler ensemble pour résoudre un problème. Ensuite, un algorithme est créé pour faire correspondre des entrées à des résultats.
L’algorithme permet à l’ordinateur d’apprendre de nouvelles choses à partir des informations qu’il reçoit. Le réseau de neurones de l’ordinateur lui permet d’analyser des exemples et de devenir meilleur dans une tâche donnée. Ces exemples sont étiquetés, ce qui aide l’ordinateur à apprendre. C’est pourquoi les ordinateurs peuvent parfois reconnaître des objets sur des images mieux que les humains.
Les réseaux de neurones artificiels sont similaires au cerveau humain. Ils apprennent en étudiant des exemples, pas en étant programmés directement. Il existe trois façons d’apprendre :
- L’apprentissage supervisé : L’ordinateur s’entraîne en utilisant des données étiquetées avec des résultats attendus. Il ajuste sa façon de travailler pour obtenir les résultats souhaités. C’est comme donner à l’ordinateur des exemples avec des réponses et le laisser apprendre à partir d’eux.
- L’apprentissage non supervisé : L’ordinateur analyse des données qui ne sont pas étiquetées. Il essaie de comprendre à quel point il se rapproche du résultat souhaité grâce à une fonction spéciale. Il s’adapte ensuite en fonction de ce qu’il apprend. C’est comme si l’ordinateur explorait des données et devait décider par lui-même ce qui est important.
- L’apprentissage renforcé : L’ordinateur apprend progressivement en recevant des récompenses pour de bonnes actions et des punitions pour de mauvaises actions. C’est comme si l’ordinateur expérimentait et apprenait par essais et erreurs, un peu comme le cerveau humain.