Voici un résultat d’une répétition d’expériences de la feuille de calculs de la leçon précédente, chaque bâton bleu représente le fait que la machine a gagné :
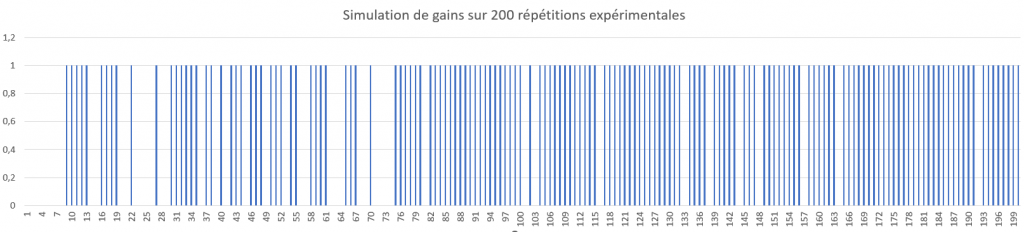
Quelle conclusion peut-on en tirer ?
Comment la machine apprend-elle ?
À la fin de la partie, si la machine a perdu, on va simplement ne pas remettre les billes jouées (stockées dans les récipients) dans les verres dont elles proviennent. On les remet dans la réserve. C’est une punition (terme consacré en apprentissage machine). Cela correspond à un mauvais choix dans la base des possibilités de jeu. Si la machine a gagné, on va remettre ces billes dans les verres en en ajoutant une (prise de la réserve) de la même couleur. C’est une récompense.
L’idée sous-jacente à l’apprentissage par renforcement repose sur le principe suivant : si la machine a subi une défaite, cela signifie que les séquences de coups qu’elle a jouées ont abouti à un résultat indésirable, et donc, on souhaite réduire la probabilité qu’elle répète ces mêmes séquences. Pour ce faire, on évite de remettre les billes dans les verres, de manière à diminuer les chances de répéter ces coups peu fructueux. En revanche, si la machine a remporté la partie, cela signifie que les séquences de coups qu’elle a utilisées ont conduit à un succès, et donc, on souhaite encourager sa répétition. Pour cela, on augmente les probabilités que la machine reproduise ces séquences en ajoutant des billes de la couleur jouée dans le verre. Cette activité résume l’essence même de l’apprentissage par renforcement.
On peut faire jouer quelques parties à la machine contre des humain·es. On verra qu’elle perd de moins en moins souvent et qu’elle devient relativement bonne au bout de dix à quinze parties, excellente au bout de vingt. Afin d’éviter le souci de machines qui n’auraient pas appris au bout de 10-15 parties, on peut mettre en commun toutes les machines à la fin pour discussion.
Apprentissage par renforcement
L’algorithme mis en place dans l’activité est un véritable algorithme d’apprentissage par renforcement, dans une version simplissime. Le principe de l’apprentissage par renforcement est le suivant : un agent fait des actions au hasard dépendant de l’état d’un environnement (éventuellement aléatoire d’ailleurs) et, en fonction du résultat obtenu, les choix sont récompensés ou punis, c’est-à-dire que les probabilités de faire lesdites actions dans le même état de l’environnement sont augmentées ou diminuées.
Les paramètres du renforcement
Tout d’abord, il convient de remarquer que la machine n’apprend pas toute seule. L’algorithme d’apprentissage est un algorithme comme un autre. Et il y a plein de choix humains dans cet algorithme.
Premièrement, les récompenses et les punitions sont à la discrétion du·de la programmeur·se. Par exemple, ici, nous avons fait le choix d’initialiser avec deux billes de chaque couleur mais nous aurions pu en mettre trois, quatre ou plus. Cela changerait le degré de punition et de renforcement des premières parties. Nous pourrions également imaginer renforcer ou punir plus les coups de la fin que ceux du début. Nous pourrions aussi récompenser beaucoup plus (en ajoutant deux ou trois billes des couleurs jouées).
Deuxièmement, il faut fixer les objectifs et savoir ce qu’on punit et ce qu’on récompense. Dans un jeu, les choses sont assez claires, l’environnement est simple. On récompense les victoires, on punit les défaites. Mais, par exemple, s’il y a possibilité de match nul, est-ce qu’on le punit ou est-ce qu’on le récompense ? Si le match nul est un bon résultat (parce qu’il n’y a pas de stratégie gagnante, comme au morpion), il faut le récompenser. Mais s’il y a possibilité de victoire, existence d’une stratégie gagnante, il vaut mieux ne pas trop le récompenser, voire le punir. Et tout ceci est affaire d’essais et d’erreurs mais aussi de savoir-faire. Si on sort des jeux, les problèmes peuvent devenir encore plus compliqués : imaginons qu’on veuille faire prendre des décisions à une voiture autonome, à quels degrés punit-on et renforce-t-on les divers résultats ?
Enfin, dans l’activité ci-dessus, on peut se poser la question de l’adversaire. Vaut-il mieux jouer au hasard contre la machine ou jouer en connaissant la stratégie gagnante (mode expert) ? L’apprentissage s’en ressent. Il se trouve que c’est beaucoup plus efficace contre un·e adversaire qui connaît la stratégie gagnante.
Pour tester ces divers modes d’apprentissage et jouer avec tous ces paramètres, on pourra utiliser l’application développée par Éric Duchêne ICI
Et sans humain ? : l’apprentissage par renforcement autonome
On pourrait penser que nous sommes arrivés à une contradiction. D’un côté, l’apprentissage est efficace contre un·e expert·e. De l’autre, le grand intérêt de l’apprentissage par renforcement vient quand on ne connaît pas la stratégie optimale, donc quand il n’y a pas d’expert·e. Comment s’en sortir ?
Heureusement, il y a une solution : faire jouer la machine contre elle-même. Il n’y a que des avantages : plus besoin d’humain·e (pour jouer) donc gain de temps, plus besoin de connaître la stratégie a priori, une vitesse d’apprentissage très bonne.
Voici un exemple à télécharger : ICI
Voici un résultat d’une répétition d’expériences, chaque bâton bleu représente le fait que la machine a gagné :

Pour aller plus loin dans l’expérience une simulation d’apprentissage par la machine du jeu de Nim version Fort Boyard :
Attention le fichier est volumineux : ICI
Source : culture Sciences Physiques